Benthos + NeonDB + Hasura
In this document we'll explain how to set up a simple data pipeline that pulls data from indexed.xyz, processes it, and inserts it into a Postgres database. Once the data is stored in Postgres (we're using NeonDB because it's neat!) we'll show you how to connect Hasura to query the data. You can also query the data directly in Postgres, or use what ever tool you've already got connected.
Set Up a Benthos Pipeline
First, you’ll need to install Benthos as described here. Try not to laugh at the blob, you may hurt its feelings.
The following configuration can be tweaked to your needs, it includes the following steps:
- Pull the data for a specific smart contract from the indexed.xyz R2 container using the S3 API. Make sure to edit the endpoint URL to include the correct prefix for the smart contract & event you’re interested in. For this example, we're using the Bored Ape Yacht Club's contract
0xbc4ca0eda7647a8ab7c2061c2e118a18a936f13d. - Maps the decoded parquet files into usable variables, pulling one of the nested fields into separate columns for ease of use.
- Insert the values into a table in Postgres, creating that table if it doesn’t exist.
http:
enabled: true
address: 0.0.0.0:4195
root_path: /benthos
debug_endpoints: false
cert_file: ''
key_file: ''
cors:
enabled: false
allowed_origins: []
basic_auth:
enabled: false
realm: restricted
username: ''
password_hash: ''
algorithm: sha256
salt: ''
input:
label: ''
aws_s3:
bucket: 'indexed-xyz-wnam'
region: 'auto'
prefix: '/ethereum/raw/logs/v2.0.0/dt=2020-02-20/'
endpoint: 'https://ed5d915e0259fcddb2ab1ce5592040c3.r2.cloudflarestorage.com'
credentials:
id: 43c31ff797ec2387177cabab6d18f15a
secret: afb354f05026f2512557922974e9dd2fdb21e5c2f5cbf929b35f0645fb284cf7
buffer:
none: {}
pipeline:
threads: -1
processors:
- parquet_decode:
byte_array_as_string: true
- mapping: |
mapped.to_address = this.event_params.list.index(0).element.string()
mapped.from_address = this.event_params.list.index(1).element.string()
mapped.value = this.event_params.list.index(2).egement.string()
mapped.id = this.id.string()
mapped.event_signature = this.event_signature.string()
mapped.address = this.address.string()
mapped.transaction_hash = this.transaction_hash.string()
mapped.log_index = this.log_index
mapped.data = this.data.string()
mapped.topics = this.topics.string()
mapped.block_number = this.block_number
mapped.block_hash = this.block_hash.string()
mapped.block_time = this.block_time
- split:
size: 1
output:
label: ''
sql_insert:
init_statement: |2
CREATE TABLE IF NOT EXISTS events (
id VARCHAR,
event_signature VARCHAR,
to_address VARCHAR,
from_address VARCHAR,
value VARCHAR,
address VARCHAR,
transaction_hash VARCHAR,
log_index BIGINT,
data VARCHAR,
topics VARCHAR,
block_number BIGINT,
block_hash VARCHAR,
block_time BIGINT
);
driver: postgres
dsn: postgres://username:password@summer-waterfall-1234.us-west-2.aws.neon.tech/yourdbname?options=project%3Dsummer-waterfall-1234&sslmode=require
table: events
columns:
[
'id',
'event_signature',
'to_address',
'from_address',
'value',
'address',
'transaction_hash',
'log_index',
'data',
'topics',
'block_number',
'block_hash',
'block_time',
]
args_mapping: root = [mapped.id, mapped.event_signature, mapped.to_address, mapped.from_address, mapped.value, mapped.address, mapped.transaction_hash, mapped.log_index, mapped.data, mapped.topics, mapped.block_number, mapped.block_hash, mapped.block_time]
max_in_flight: 64
batching:
count: 100
period: 100ms
logger:
level: INFO
format: logfmt
add_timestamp: false
timestamp_name: time
message_name: msg
static_fields:
'@service': benthos
file:
path: ''
rotate: false
rotate_max_age_days: 0
metrics:
prometheus:
use_histogram_timing: false
histogram_buckets: []
add_process_metrics: false
add_go_metrics: false
push_url: ''
push_interval: ''
push_job_name: benthos_push
push_basic_auth:
username: ''
password: ''
file_output_path: ''
mapping: ''
tracer:
none: {}
shutdown_delay: ''
shutdown_timeout: 20s
What you'll need to modify:
⚠️ You can get your dsn connection string from either NeonDB or from Hasura. When connecting Hasura to NeonDB, it creates a new database in NeonDB that only has permissions for the Hasura user, you can also manually connect the NeonDB postgres endpoint to Hasura and keep using that dsn.
If you use the NeonDB connection string, you’ll need to make sure to add the additional option ?options=project%3D<your-project-name> to the connection string, where <your-project-name> is the first part of the hostname.
You may also want to tweak the batch count, period, or the skip processing step value. Benthos output may overwhelm the Postgres client, causing unwanted errors if these values are too permissive. The current settings may mean that it will take a while to run the whole pipeline.
Another thing to keep in mind is that this will download and insert everything in the partition, which is more than just the events for your selected smart contract. It's quite a lot of data, so you may want to add a filtering step in Benthos, or restrict your download to a single year by adding dt=YYYY to the end of the prefix in the config file.
Finally, since there's no primary key on the database, if you re-run this pipeline, it'll duplicate data. You can try adding a primary key to id, but keep in mind that the data may change between versions, or there may be some blocks with incomplete id data.
NeonDB
If you don't already have a NeonDB account, go ahead and sign up for a free one here.
The Hasura connector for NeonDB takes care of most of what you need, but if you want to work directly with NeonDB, you can do that as well by just using the DATABASE_URL provided in their environment config, with the caveat that you will need to add an additional option parameter specifying the project you’re using, like this:
postgres://username:[email protected]/neondb**?options=project%3Dep-old-voice-1234**
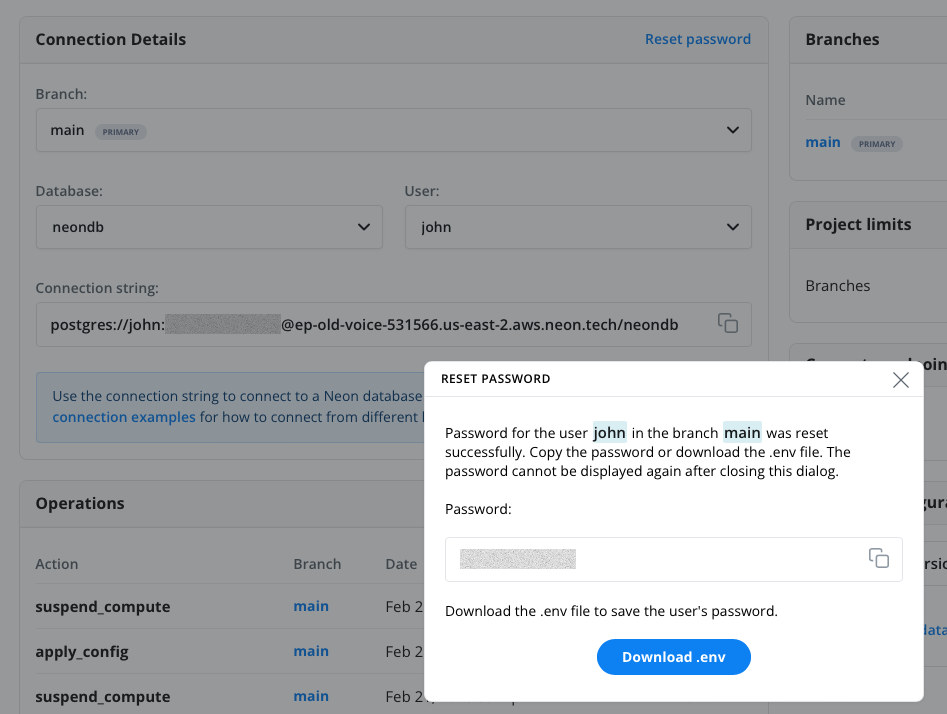
The environment config is offered up the first time you create a database, make sure to download it to have access to the full connection string. If you forgot this step, then click the Reset Password link in your main dashboard, then download the env file that is generated.
Hasura
Connecting NeonDB
To connect NeonDB to Hasura, it’s mostly a one-click process that you can follow here. This process will create a new database and also a sample set of tables that are unrelated to our project.
Getting the Connection String
To get the environment variables and the dsn connection string to use, launch the Hasura console, then click the project name in the top right-hand corner. This will load the following screen where you can click on the Env link to see your environment variables. The PG_DATABASE_URL is what you’re looking for. This URL will work out of the box as it already includes the option to specify the correct project.
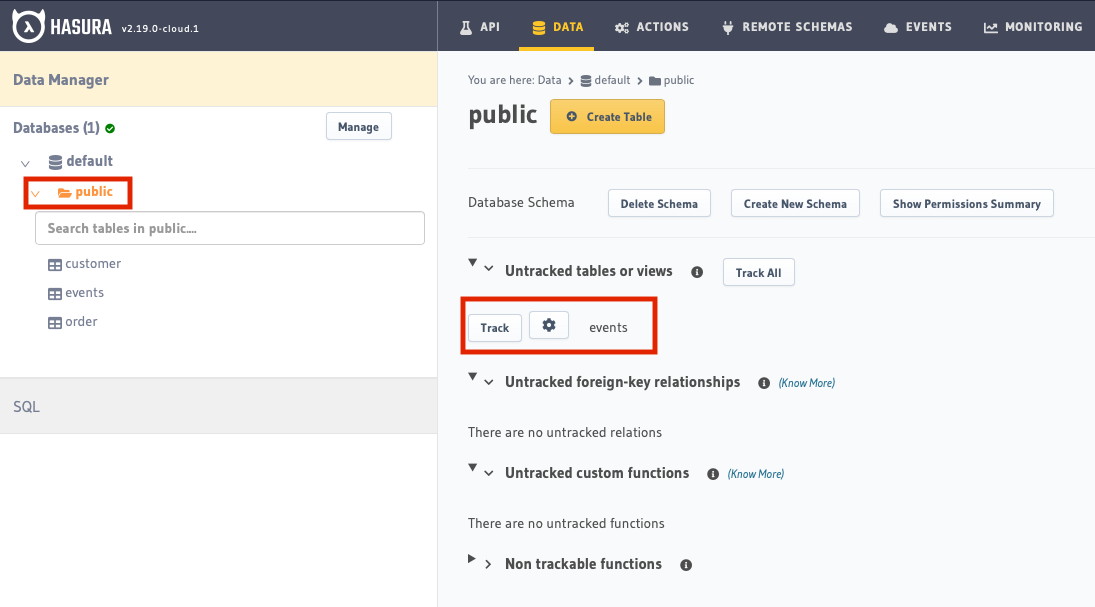
Tracking the events Table
If you are running Benthos with your Hasura dsn connection, the table events won’t be tracked automatically. In order to add it to Hasura, go to the Data tab, click on the public link, and then click Track on the area to the right where it says events (or what ever you decide to name the table, just make sure to update it in the places it’s used in the config.yaml!)
Running the Pipeline
Once you have the config.yaml set up with the credentials you plan to use, it’s pretty simple to run the pipeline from your terminal:
$ benthos -c ./config.yaml
Querying the Data in Hasura
From here, if you're familiar with Hasura, you can get right to querying the data. Here's a sample query you can try to see a list of all the tokens in the Bored Ape Yacht Club collection:
query GetEvents {
eventsmore_aggregate(distinct_on: value) {
aggregate {
count
}
}
}
Let us know if you have any cool queries by contributing to this document, or sending us an email!